Downloading and streaming data using STAC metadata 
Sign up to the DEA Sandbox to run this notebook interactively from a browser
Compatability: Notebook currently compatible with the
DEA SandboxenvironmentProducts used: ga_ls8c_ard_3
IMPORTANT: This notebook provides information for downloading/streaming individual datasets using STAC. If wanting to load and analyse data from multiple datasets, we recommend using the odc-stac package. To learn more about using odc-stac to load data from Digital Earth Australia, visit the Knowledge Hub. A more general tutorial on odc-stac is also available from The Open Data Cube documentation.
Background
Digital Earth Australia (DEA) stores a range of data products on Amazon Web Service’s Simple Cloud Storage (S3) with free public access. These products can be browsed on the interactive DEA Sandbox Explorer. To make it easier to find data in the DEA archive, the DEA Sandbox Explorer also provides a SpatioTemporal Asset Catalog (STAC) endpoint for listing or searching metadata (https://explorer.dea.ga.gov.au/stac/).
STAC is a recently developed specification that provides a common language to describe geospatial information so it can more easily be indexed and discovered. DEA’s STAC metadata can be used to quickly identify all available data for a given product, location or time period. This information can then be used to efficiently download data from the cloud onto a local disk, or stream data directly into desktop GIS software like QGIS.
Description
This notebook provides a brief introduction to accessing and using DEA’s STAC metadata:
How to construct a STAC metadata API call
How to search for STAC metadata and load the results into Python
How to inspect and plot the unique STAC Items contained in the metadata
How to inspect assets contained within a STAC Item
How to download data using STAC metadata
How to stream data into Python and QGIS using STAC metadata (without downloading it first)
Getting started
To run this analysis, run all the cells in the notebook, starting with the “Load packages” cell.
Load packages
Import Python packages that are used for the analysis.
[1]:
import urllib.request, json
import geopandas as gpd
import xarray as xr
import rioxarray
from pprint import pprint
import odc.aws
import odc.geo.xr
from dea_tools.datahandling import load_reproject
Searching STAC metadata
Construct the STAC API call
First we need to set up some analysis parameters that will be used to search for metadata. This includes product, which is the same product name used to load data directly using dc.load (see Introduction to loading data).
For a full list of available products, browse the DEA Sandbox Explorer.
[2]:
product = 'ga_ls8c_ard_3'
start_time = '2020-01-01'
end_time = '2020-01-31'
bbox = [149.0, -35.0, 150.2, -36.0]
We can now combine the parameters above to create a URL that will be used to query DEA’s STAC metadata. This metadata can be previewed in another tab by clicking the URL.
[3]:
root_url = 'https://explorer.dea.ga.gov.au/stac'
stac_url = f'{root_url}/search?collection={product}&time={start_time}/{end_time}&bbox={str(bbox).replace(" ", "")}&limit=6'
print(stac_url)
https://explorer.dea.ga.gov.au/stac/search?collection=ga_ls8c_ard_3&time=2020-01-01/2020-01-31&bbox=[149.0,-35.0,150.2,-36.0]&limit=6
Load STAC metadata
We can now load metadata from the URL above into Python. STAC metadata is stored in JSON format, which we can read into nested Python dictionaries using the json Python module.
[4]:
with urllib.request.urlopen(stac_url) as url:
data = json.loads(url.read().decode())
pprint(data, depth=1)
{'context': {...},
'features': [...],
'links': [...],
'numberMatched': 10,
'numberReturned': 6,
'type': 'FeatureCollection'}
Inspecting STAC Items
In the output above, the numberReturned value indicates our search returned six unique results. These results are known as STAC Items. These are an atomic collection of inseparable data and metadata, such as a unique satellite dataset.
Data for each STAC Item is contained in the metadata’s list of features:
[5]:
pprint(data['features'], depth=2)
[{'assets': {...},
'bbox': [...],
'collection': 'ga_ls8c_ard_3',
'geometry': {...},
'id': '6419eb80-5e3c-42ee-8b57-1fcf99d51fb0',
'links': [...],
'properties': {...},
'stac_extensions': [...],
'stac_version': '1.0.0',
'type': 'Feature'},
{'assets': {...},
'bbox': [...],
'collection': 'ga_ls8c_ard_3',
'geometry': {...},
'id': 'b72d8087-023d-4f84-9568-2ac4401244a4',
'links': [...],
'properties': {...},
'stac_extensions': [...],
'stac_version': '1.0.0',
'type': 'Feature'},
{'assets': {...},
'bbox': [...],
'collection': 'ga_ls8c_ard_3',
'geometry': {...},
'id': '1ef09805-31dc-4dab-95d7-a09fe64ba821',
'links': [...],
'properties': {...},
'stac_extensions': [...],
'stac_version': '1.0.0',
'type': 'Feature'},
{'assets': {...},
'bbox': [...],
'collection': 'ga_ls8c_ard_3',
'geometry': {...},
'id': 'bb16a74c-652e-4764-aa77-2e80186bac5d',
'links': [...],
'properties': {...},
'stac_extensions': [...],
'stac_version': '1.0.0',
'type': 'Feature'},
{'assets': {...},
'bbox': [...],
'collection': 'ga_ls8c_ard_3',
'geometry': {...},
'id': '2b169746-644a-4ac9-aba9-6f059c5f09e0',
'links': [...],
'properties': {...},
'stac_extensions': [...],
'stac_version': '1.0.0',
'type': 'Feature'},
{'assets': {...},
'bbox': [...],
'collection': 'ga_ls8c_ard_3',
'geometry': {...},
'id': '70f0d5f2-d0d0-4ae7-af92-7b4aa0a8d793',
'links': [...],
'properties': {...},
'stac_extensions': [...],
'stac_version': '1.0.0',
'type': 'Feature'}]
STAC’s features are stored as GeoJSON, a widely used file format for storing geospatial vector data. This means we can easily convert it to a spatial object using the geopandas Python module. This allows us to plot and inspect the spatial extents of our data:
[6]:
# Convert features to a GeoDataFrame
gdf = gpd.GeoDataFrame.from_features(data['features'])
# Plot the footprints of each dataset
gdf.plot(alpha=0.8, edgecolor='black')
[6]:
<Axes: >
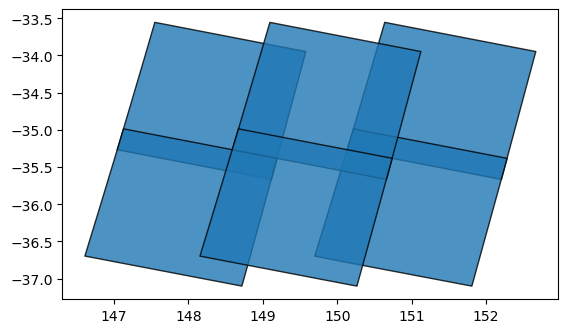
If we print the GeoDataFrame itself, we can see that it contains useful metadata fields that provide information about each dataset:
[7]:
gdf.head(1)
[7]:
| geometry | title | gsd | gqa:abs_x | gqa:abs_y | gqa:cep90 | proj:epsg | fmask:snow | gqa:abs_xy | gqa:mean_x | ... | created | gqa:abs_iterative_mean_x | gqa:abs_iterative_mean_y | landsat:landsat_scene_id | gqa:abs_iterative_mean_xy | landsat:collection_number | landsat:landsat_product_id | landsat:collection_category | cubedash:region_code | datetime | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | POLYGON ((149.11285 -35.66597, 149.11281 -35.6... | ga_ls8c_ard_3-1-0_091084_2020-01-07_final | 15.0 | 0.23 | 0.22 | 0.34 | 32655 | 0.0 | 0.31 | -0.06 | ... | 2020-06-12T04:13:56.338677Z | 0.14 | 0.12 | LC80910842020007LGN00 | 0.18 | 1 | LC08_L1TP_091084_20200107_20200114_01_T1 | T1 | 091084 | 2020-01-07T23:56:40.668676Z |
1 rows × 53 columns
We can use this to learn more about our data. For example, we can plot our datasets using the eo:cloud_cover field to show what percent of each dataset was obscured by cloud (yellow = high cloud cover):
[8]:
# Colour features by cloud cover
gdf.plot(column='eo:cloud_cover',
cmap='viridis',
alpha=0.8,
edgecolor='black',
legend=True)
[8]:
<Axes: >
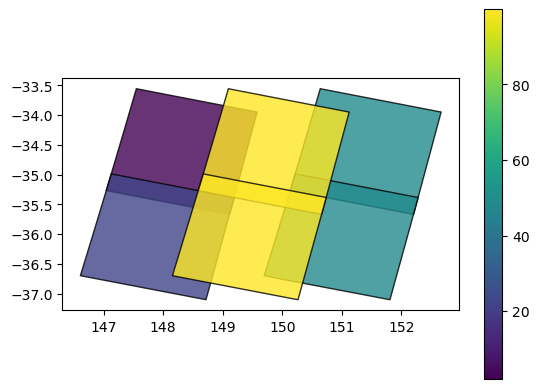
Inspecting assets
Each STAC Item listed in features can contain multiple assets. This assets represent unique data files or layers, for example individual remote sensing bands. For DEA’s Landsat Surface Reflectance products, these can include 'nbart_blue', 'nbart_green', 'nbart_red', 'nbart_nir' etc:
[9]:
stac_item = data['features'][0]
pprint(stac_item['assets'], depth=1)
{'nbart_blue': {...},
'nbart_coastal_aerosol': {...},
'nbart_green': {...},
'nbart_nir': {...},
'nbart_panchromatic': {...},
'nbart_red': {...},
'nbart_swir_1': {...},
'nbart_swir_2': {...},
'oa_azimuthal_exiting': {...},
'oa_azimuthal_incident': {...},
'oa_combined_terrain_shadow': {...},
'oa_exiting_angle': {...},
'oa_fmask': {...},
'oa_incident_angle': {...},
'oa_nbart_contiguity': {...},
'oa_relative_azimuth': {...},
'oa_relative_slope': {...},
'oa_satellite_azimuth': {...},
'oa_satellite_view': {...},
'oa_solar_azimuth': {...},
'oa_solar_zenith': {...},
'oa_time_delta': {...}}
Importantly, each asset (for example, 'nbart_blue') provides a unique URL (href) that can be used to access or download the data. In this case, the s3:// prefix indicates our data is stored in the cloud on Amazon S3.
[10]:
pprint(stac_item['assets']['nbart_blue'])
{'eo:bands': [{'name': 'nbart_blue'}],
'href': 's3://dea-public-data/baseline/ga_ls8c_ard_3/091/084/2020/01/07/ga_ls8c_nbart_3-1-0_091084_2020-01-07_final_band02.tif',
'proj:epsg': 32655,
'proj:shape': [7881, 7831],
'proj:transform': [30.0, 0.0, 503685.0, 0.0, -30.0, -3712785.0, 0.0, 0.0, 1.0],
'roles': ['data'],
'title': 'nbart_blue',
'type': 'image/tiff; application=geotiff; profile=cloud-optimized'}
Downloading files using STAC
Now that we have a URL, we can use this to download data to our local disk. For example, we may want to download data for the 'nbart_blue' satellite band in our STAC Item. We can do this using the s3_download function from odc.aws:
[11]:
# Get URL then download
url = stac_item['assets']['nbart_blue']['href']
odc.aws.s3_download(url)
[11]:
'ga_ls8c_nbart_3-1-0_091084_2020-01-07_final_band02.tif'
To verify that this file downloaded correctly, we can load it into our notebook as an xarray.Dataset() using rioxarray.open_rasterio:
[12]:
# Load data as an xarray.Dataset()
downloaded_ds = rioxarray.open_rasterio('ga_ls8c_nbart_3-1-0_091084_2020-01-07_final_band02.tif')
# Plot a small subset of the data
downloaded_ds.isel(x=slice(2000, 3000), y=slice(2000, 3000)).plot(robust=True)
[12]:
<matplotlib.collections.QuadMesh at 0x7f1f9665ec80>
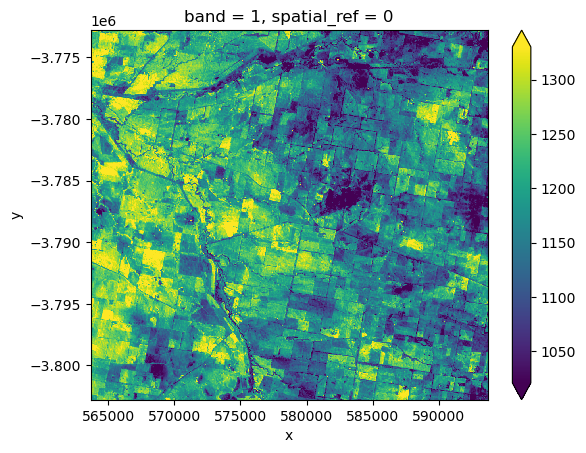
Note: If this notebook is being run on the DEA Sandbox, the saved file will appear in the
How_to_guidesdirectory in the JupyterLab File Browser. To save it to your local PC, right click on the file and clickDownload.
Downloading multiple files
To download data from the 'nbart_blue' band for each of the six STAC Items returned by our search:
# Get list of all URLs for the 'nbart_blue' band
asset = 'nbart_blue'
urls = [stac_item['assets'][asset]['href'] for stac_item in data['features']]
# Download each URL
for url in urls:
print(url)
odc.aws.s3_download(url)
To download all available bands (i.e. assets) for a single STAC Item:
# Get list of all URLs for all assets in the first STAC Item
stac_item = data['features'][0]
urls = [asset['href'] for asset in stac_item['assets'].values()]
# Download each URL
for url in urls:
print(url)
odc.aws.s3_download(url)
Streaming data without downloading
Due to the increasing size of satellite datasets, downloading data directly to your own local disk can be time-consuming and slow. Sometimes, it is better to stream data directly from the cloud without downloading it first. This can be particularly powerful for data that is stored in the Cloud Optimised GeoTIFF (COG) format which is optimised for efficiently streaming small chunks of an image at a time.
This section demonstrates how data can be streamed directly from the cloud into both Python and the QGIS GIS software. As a first step, we need to convert our Amazon S3 URL (e.g. s3://) into HTTPS format (e.g. https://) so that it can be read more easily:
[13]:
# Get URL
url = stac_item['assets']['nbart_blue']['href']
# Get https URL
bucket, key = odc.aws.s3_url_parse(url)
https_url = f'https://dea-public-data.s3.ap-southeast-2.amazonaws.com/{key}'
https_url
[13]:
'https://dea-public-data.s3.ap-southeast-2.amazonaws.com/baseline/ga_ls8c_ard_3/091/084/2020/01/07/ga_ls8c_nbart_3-1-0_091084_2020-01-07_final_band02.tif'
Streaming data into Python
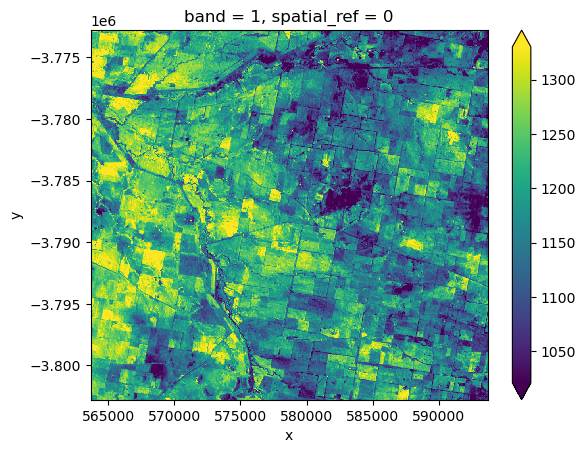
To stream data directly from the cloud into an xarray.Dataset() format so it can be analysed in Python, we can supply the HTTPS URL above directly to the rioxarray.open_rasterio function:
[14]:
# Load data as an xarray.Dataset()
streamed_ds = rioxarray.open_rasterio(https_url)
# Plot a small subset of the data
streamed_ds.isel(x=slice(2000, 3000), y=slice(2000, 3000)).plot(robust=True)
[14]:
<matplotlib.collections.QuadMesh at 0x7f1f97115ab0>
Streaming and reprojecting data
The code above will stream the entire dataset from the cloud into a xarray.Dataset(). Sometimes, however, we may only want to stream a portion of large dataset into a spatial grid (e.g. resolution and coordinate reference system) that exactly matches data we have already loaded using Datacube.
For example, we may have already used dc.load to load example data from the datacube into the Australian Albers projection and a 30 m pixel resolution:
[15]:
import datacube
# Connect to datacube
dc = datacube.Datacube(app='Downloading_data_with_STAC')
# Load data from datacube with a 300m cell size, Australian Albers CRS
ds = dc.load(product='ga_ls8c_ard_3',
time='2020-01-07',
x=(149.08, 149.16),
y=(-35.25, -35.33),
resolution=(-30, 30),
output_crs='EPSG:3577',
dask_chunks={})
ds
[15]:
<xarray.Dataset> Size: 6MB
Dimensions: (time: 1, y: 328, x: 280)
Coordinates:
* time (time) datetime64[ns] 8B 2020-01-07T23:56:40....
* y (y) float64 3kB -3.953e+06 ... -3.963e+06
* x (x) float64 2kB 1.545e+06 ... 1.554e+06
spatial_ref int32 4B 3577
Data variables: (12/22)
nbart_coastal_aerosol (time, y, x) int16 184kB dask.array<chunksize=(1, 328, 280), meta=np.ndarray>
nbart_blue (time, y, x) int16 184kB dask.array<chunksize=(1, 328, 280), meta=np.ndarray>
nbart_green (time, y, x) int16 184kB dask.array<chunksize=(1, 328, 280), meta=np.ndarray>
nbart_red (time, y, x) int16 184kB dask.array<chunksize=(1, 328, 280), meta=np.ndarray>
nbart_nir (time, y, x) int16 184kB dask.array<chunksize=(1, 328, 280), meta=np.ndarray>
nbart_swir_1 (time, y, x) int16 184kB dask.array<chunksize=(1, 328, 280), meta=np.ndarray>
... ...
oa_relative_slope (time, y, x) float32 367kB dask.array<chunksize=(1, 328, 280), meta=np.ndarray>
oa_satellite_azimuth (time, y, x) float32 367kB dask.array<chunksize=(1, 328, 280), meta=np.ndarray>
oa_satellite_view (time, y, x) float32 367kB dask.array<chunksize=(1, 328, 280), meta=np.ndarray>
oa_solar_azimuth (time, y, x) float32 367kB dask.array<chunksize=(1, 328, 280), meta=np.ndarray>
oa_solar_zenith (time, y, x) float32 367kB dask.array<chunksize=(1, 328, 280), meta=np.ndarray>
oa_time_delta (time, y, x) float32 367kB dask.array<chunksize=(1, 328, 280), meta=np.ndarray>
Attributes:
crs: EPSG:3577
grid_mapping: spatial_refWe can now use the rio_slurp_xarray function to stream the data we identified using STAC into a format that is consistent with the ds data we loaded using the Datacube. Note that gbox=ds.odc.geobox.compat tells the function to load the data to match ds’s 5000 m Australian Albers spatial grid. The output should therefore appear far more pixelated than previous plots:
[16]:
# Load data as an xarray.Dataset()
streamed_ds = load_reproject(path=https_url, how=ds.odc.geobox)
# Verify that data contains an Open Data Cube geobox
streamed_ds.plot(robust=True)
[16]:
<matplotlib.collections.QuadMesh at 0x7f1f87fc37c0>
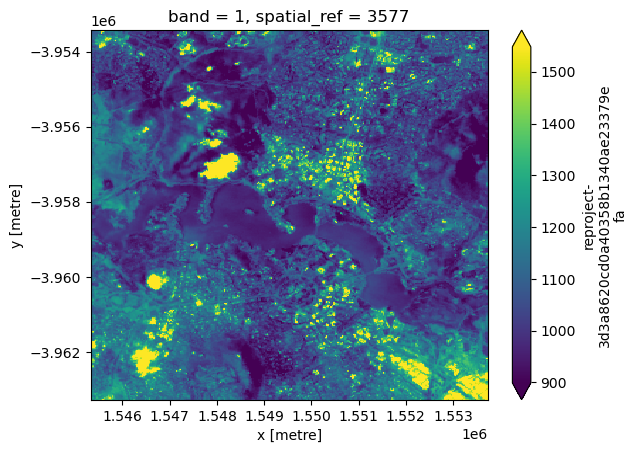
Verify that both datasets share the same spatial grid:
[17]:
ds.odc.geobox == streamed_ds.odc.geobox
[17]:
True
Note: For more about reprojecting data, see the Reprojecting datacube and raster data notebook.
Streaming data into QGIS
To stream data directly into a GIS software like QGIS without having to download it, first select and copy the HTTPS URL above (e.g. 'https://dea-public-data...) to our clipboard, then open QGIS. In QGIS, click Layer > Add Layer > Add Raster Layer:
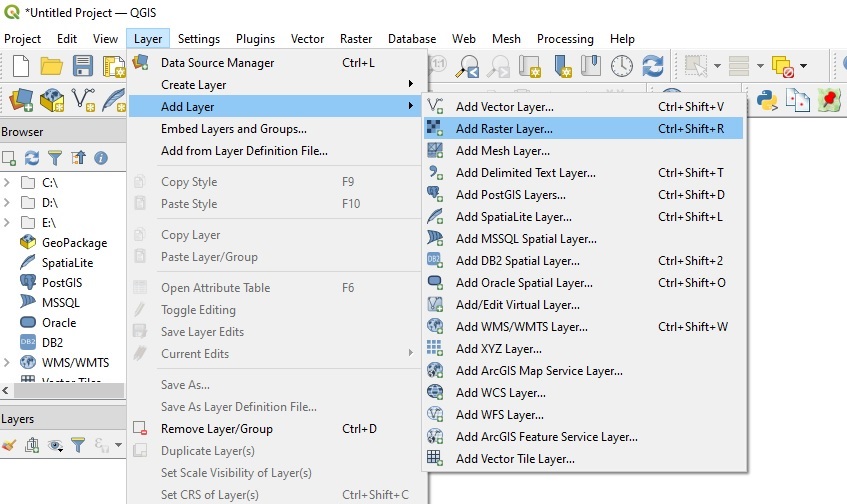
On the Data Source Manager | Raster dialogue, click Protocol: HTTP(S), cloud, etc. Ensure Type is set to HTTP/HTTPS/FTP, and paste the URL you copied into the URI box:
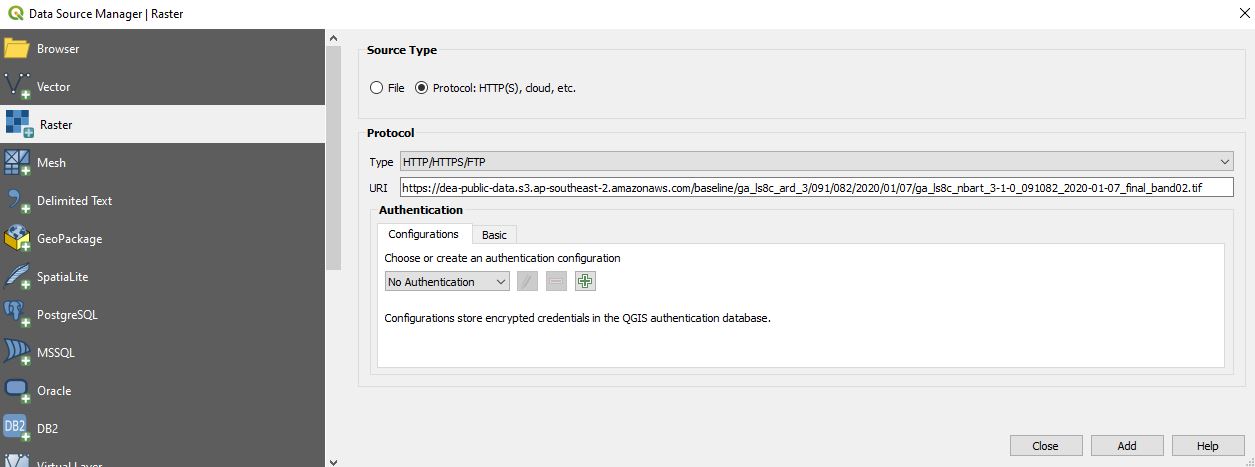
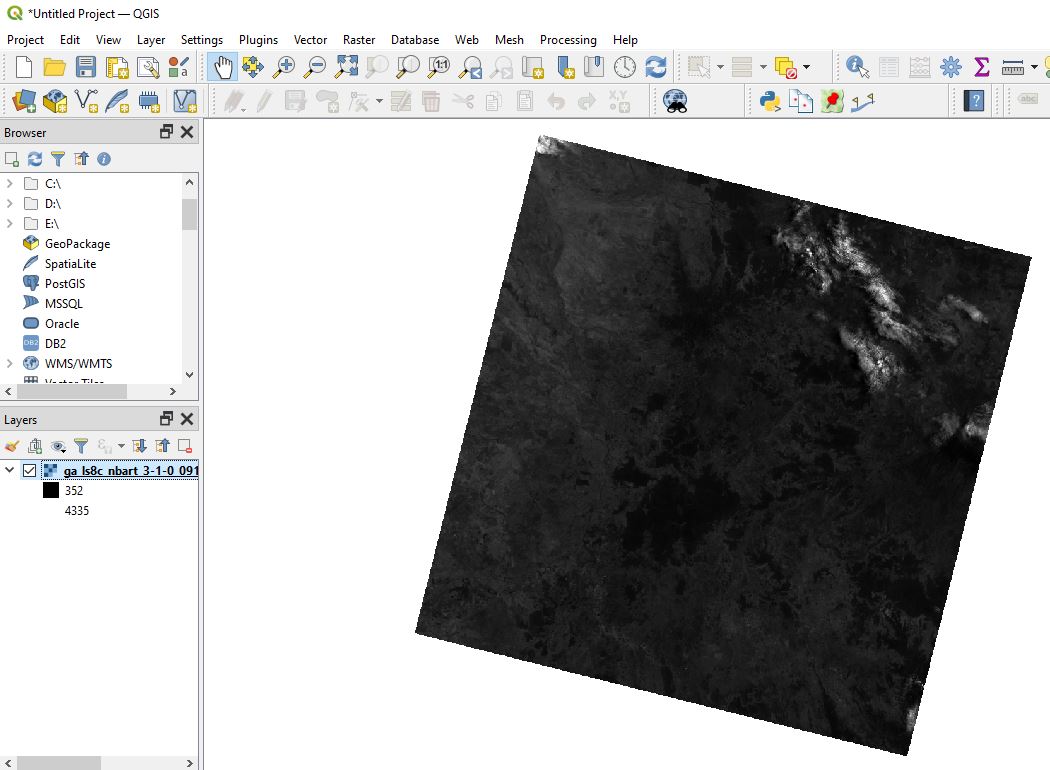
Click Add, then Close. After a few moments, the image we identified using STAC will appear on the map. This data is being streamed directly from the cloud - no downloading required!
Additional information
License: The code in this notebook is licensed under the Apache License, Version 2.0. Digital Earth Australia data is licensed under the Creative Commons by Attribution 4.0 license.
Contact: If you need assistance, please post a question on the Open Data Cube Discord chat or on the GIS Stack Exchange using the open-data-cube tag (you can view previously asked questions here). If you would like to report an issue with this notebook, you can file one on
GitHub.
Last modified: December 2023
Compatible datacube version:
[18]:
print(datacube.__version__)
1.9.9
Tags
Tags: sandbox compatible, STAC, S3, exporting data, streaming data, QGIS, reprojecting data, rio_slurp_xarray, GeoBox, rioxarray.open_rasterio