Detecting water with radar 
Sign up to the DEA Sandbox to run this notebook interactively from a browser
Compatibility: Notebook currently compatible with the
DEA Sandboxenvironment onlyProducts used: s1_gamma0_geotif_scene
Background
Over 40% of the world’s population lives within 100 km of the coastline. However, coastal environments are constantly changing, with erosion and coastal change presenting a major challenge to valuable coastal infrastructure and important ecological habitats. Up-to-date data on the position of the coastline is essential for coastal managers to be able to identify and minimise the impacts of coastal change and erosion.
While coastlines can be mapped using optical data (demonstrated in the Coastal Erosion notebook), these images can be strongly affected by the weather, especially through the presence of clouds, which obscure the land and water below. This can be a particular problem in cloudy regions (e.g. southern Australia) or areas where wet season clouds prevent optical satellites from taking clear images for many months of the year.
Sentinel-1 use case
Radar observations are largely unaffected by cloud cover, so can take reliable measurements of areas in any weather. Radar data is readily available from the ESA/EC Copernicus program’s Sentinel-1 satellites. The two satellites provide all-weather observations, with a revisit time of 6 days. By developing a process to classify the observed pixels as either water or land, it is possible to identify the shoreline from radar data.
Description
In this example, we use data from the Sentinel-1 satellites to build a classifier that can determine whether a pixel is water or land in radar data. Specifically, this notebook uses an analysis-ready radar product known as backscatter, which describes the strength of the signal recieved by the satellite. The worked example takes users through the code required to:
Load Sentinel-1 backscatter data for an area of interest
Visualise the returned data.
Perform pre-processing steps on the Sentinel-1 bands.
Design a classifier to distinguish land and water.
Apply the classifier to the area of interest and interpret the results.
Investigate how to identify coastal change or the effect of tides.
Getting started
To run this analysis, run all the cells in the notebook, starting with the “Load packages” cell.
After finishing the analysis, return to the “Analysis parameters” cell, modify some values (e.g. choose a different location or time period to analyse) and re-run the analysis. There are additional instructions on modifying the notebook at the end.
Load packages
Load key Python packages and supporting functions for the analysis.
[39]:
%matplotlib inline
import datacube
import numpy as np
import xarray as xr
import matplotlib.pyplot as plt
from scipy.ndimage import uniform_filter
import sys
sys.path.insert(1, '../Tools/')
from dea_tools.plotting import display_map
Connect to the datacube
Activate the datacube database, which provides functionality for loading and displaying stored Earth observation data.
[40]:
dc = datacube.Datacube(app="Radar_water_detection")
Analysis parameters
The following cell sets the parameters, which define the area of interest and the length of time to conduct the analysis over. The parameters are
latitude: The latitude range to analyse (e.g.(-11.288, -11.086)). For reasonable loading times, make sure the range spans less than ~0.1 degrees.longitude: The longitude range to analyse (e.g.(130.324, 130.453)). For reasonable loading times, make sure the range spans less than ~0.1 degrees.
If running the notebook for the first time, keep the default settings below. This will demonstrate how the analysis works and provide meaningful results. The example covers Melville Island, which sits off the coast of the Northern Territory, Australia. The study area also contains an additional small island, which will be useful for assessing how well radar data distinguishes between land and water.
To run the notebook for a different area, make sure Sentinel-1 data is available for the chosen area using the DEA Sandbox Explorer.
[41]:
# Define the area of interest
latitude = (-11.288, -11.086)
longitude = (130.324, 130.453)
View the selected location
The next cell will display the selected area on an interactive map. Feel free to zoom in and out to get a better understanding of the area you’ll be analysing. Clicking on any point of the map will reveal the latitude and longitude coordinates of that point.
[42]:
display_map(x=longitude, y=latitude)
[42]:
Load and view Sentinel-1 data
The first step in the analysis is to load Sentinel-1 backscatter data for the specified area of interest. Since there is no time range provided, all available data will be selected.
Please be patient. The data may take a few minutes to load. The load is complete when the cell status goes from [*] to [number].
[43]:
# Specify the parameters to query on
query = {
"x": longitude,
"y": latitude,
"product": "s1_gamma0_geotif_scene",
"output_crs": "EPSG:4326",
"resolution": (0.0001356, 0.0001356)
}
# Find all datasets matching query
dss = dc.find_datasets(**query)
# Load every 3rd dataset. Change to 1 to load every timestep
ds_s1 = dc.load(datasets=dss[::3],**query)
Once the load is complete, examine the data by printing it in the next cell. The Dimensions argument revels the number of time steps in the data set, as well as the number of pixels in the latitude and longitude dimensions.
[44]:
ds_s1
[44]:
<xarray.Dataset> Size: 102MB
Dimensions: (time: 9, latitude: 1490, longitude: 952)
Coordinates:
* time (time) datetime64[ns] 72B 2017-01-25T20:56:21.054081 ... 201...
* latitude (latitude) float64 12kB -11.29 -11.29 -11.29 ... -11.09 -11.09
* longitude (longitude) float64 8kB 130.3 130.3 130.3 ... 130.5 130.5 130.5
spatial_ref int32 4B 4326
Data variables:
vh (time, latitude, longitude) float32 51MB 0.002471 ... 0.002873
vv (time, latitude, longitude) float32 51MB 0.01467 ... 0.001843
Attributes:
crs: EPSG:4326
grid_mapping: spatial_refVisualise loaded data
Sentinel-1 backscatter data has two measurements, VV and VH, which correspond to the polarisation of the light sent and received by the satellite. VV refers to the satellite sending out vertically-polarised light and receiving vertically-polarised light back, whereas VH refers to the satellite sending out vertically-polarised light and receiving horizontally-polarised light back. These two measurement bands can tell us different information about the area we’re studying.
When working with radar backscatter, it is common to work with the data in units of decibels (dB), rather than digital number (DN) as measured by the satellite. To convert from DN to dB, we use the following formula:
[45]:
def dB_scale(data):
'''Scales a xarray.DataArray with linear DN to a dB scale.'''
# Explicitly set negative data to nan to avoid log of negative number
negative_free_data = data.where(data >= 0, np.nan)
return 10 * np.log10(negative_free_data)
Visualise VH band
[46]:
# Scale to plot data in decibels
ds_s1["vh_dB"] = dB_scale(ds_s1.vh)
# Plot all VH observations for the year
ds_s1.vh_dB.plot(cmap="Greys_r", robust=True, col="time", col_wrap=5)
plt.show()

[47]:
# Plot the average of all VH observations
mean_vh_dB = ds_s1.vh_dB.mean(dim="time")
fig = plt.figure(figsize=(7, 9))
mean_vh_dB.plot(cmap="Greys_r", robust=True)
plt.title("Average VH")
plt.show()

What key differences do you notice between each individual observation and the mean?
Visualise VV band
[48]:
# Scale to plot data in decibels
ds_s1["vv_dB"] = dB_scale(ds_s1.vv)
# Plot all VV observations for the year
ds_s1.vv_dB.plot(cmap="Greys_r", robust=True, col="time", col_wrap=5)
plt.show()

[49]:
# Plot the average of all VV observations
mean_vv_dB = ds_s1.vv_dB.mean(dim="time")
fig = plt.figure(figsize=(7, 9))
mean_vv_dB.plot(cmap="Greys_r", robust=True)
plt.title("Average VV")
plt.show()

What key differences do you notice between each individual observation and the mean? What about differences between the average VH and VV bands?
Take a look back at the map image to remind yourself of the shape of the land and water of our study area. In both bands, what distinguishes the land and the water?
Preprocessing the data through filtering
Speckle Filtering using Lee Filter
You may have noticed that the water in the individual VV and VH images isn’t a consistent colour. The distortion you’re seeing is a type of noise known as speckle, which gives the images a grainy appearence. If we want to be able to easily decide whether any particular pixel is water or land, we need to reduce the chance of misinterpreting a water pixel as a land pixel due to the noise.
Speckle can be removed through filtering. If interested, you can find a technical introduction to speckle filtering here. For now, it is enough to know that we can filter the data using the Python function defined in the next cell:
[50]:
# Adapted from https://stackoverflow.com/questions/39785970/speckle-lee-filter-in-python
def lee_filter(img, size):
"""
Applies the Lee filter to reduce speckle noise in an image.
Parameters:
img (ndarray): Input image to be filtered.
size (int): Size of the uniform filter window.
Returns:
ndarray: The filtered image.
"""
img_mean = uniform_filter(img, size)
img_sqr_mean = uniform_filter(img**2, size)
img_variance = img_sqr_mean - img_mean**2
overall_variance = np.var(img)
img_weights = img_variance / (img_variance + overall_variance)
img_output = img_mean + img_weights * (img - img_mean)
return img_output
Now that we’ve defined the filter, we can run it on the VV and VH data. You might have noticed that the function takes a size argument. This will change how blurred the image becomes after smoothing. We’ve picked a default value for this analysis, but you can experiement with this if you’re interested.
[51]:
# Define a function to apply the Lee filter to a DataArray
def apply_lee_filter(data_array, size=7):
"""
Applies the Lee filter to the provided DataArray.
Parameters:
data_array (xarray.DataArray): The data array to be filtered.
size (int): Size of the uniform filter window. Default is 7.
Returns:
xarray.DataArray: The filtered data array.
"""
data_array_filled = data_array.fillna(0)
filtered_data = xr.apply_ufunc(
lee_filter, data_array_filled,
kwargs={"size": size},
input_core_dims=[["latitude", "longitude"]],
output_core_dims=[["latitude", "longitude"]],
dask_gufunc_kwargs={"allow_rechunk": True},
vectorize=True,
dask="parallelized",
output_dtypes=[data_array.dtype]
)
return filtered_data
[52]:
# Apply the Lee filter to both VV and VH data
ds_s1["filtered_vv"] = apply_lee_filter(ds_s1.vv, size = 7)
ds_s1["filtered_vh"] = apply_lee_filter(ds_s1.vh, size = 7)
Visualise filtered data
We can now visualise the filtered bands in the same way as the original bands. Note that the filtered values must also be converted to decibels before being displayed.
Visualise filtered VH band
[53]:
# Scale to plot data in decibels
ds_s1["filtered_vh_dB"] = dB_scale(ds_s1.filtered_vh)
# Plot all filtered VH observations for the year
ds_s1.filtered_vh_dB.plot(cmap="Greys_r", robust=True, col="time", col_wrap=5)
plt.show()

[54]:
# Plot the average of all filtered VH observations
mean_filtered_vh_dB = ds_s1.filtered_vh_dB.mean(dim="time")
fig = plt.figure(figsize=(7, 9))
mean_filtered_vh_dB.plot(cmap="Greys_r", robust=True)
plt.title("Average filtered VH")
plt.show()

Visualise filtered VV band
[55]:
# Scale to plot data in decibels
ds_s1["filtered_vv_dB"] = dB_scale(ds_s1.filtered_vv)
# Plot all filtered VV observations for the year
ds_s1.filtered_vv_dB.plot(cmap="Greys_r", robust=True, col="time", col_wrap=5)
plt.show()

[56]:
# Plot the average of all filtered VV observations
mean_filtered_vv_dB = ds_s1.filtered_vv_dB.mean(dim="time")
fig = plt.figure(figsize=(7, 9))
mean_filtered_vv_dB.plot(cmap="Greys_r", robust=True)
plt.title("Average filtered VV")
plt.show()

Now that you’ve finished filtering the data, compare the plots before and after and you should be able to notice the impact of the filtering. If you’re having trouble spotting it, it’s more noticable in the VH band.
Plotting VH and VV histograms
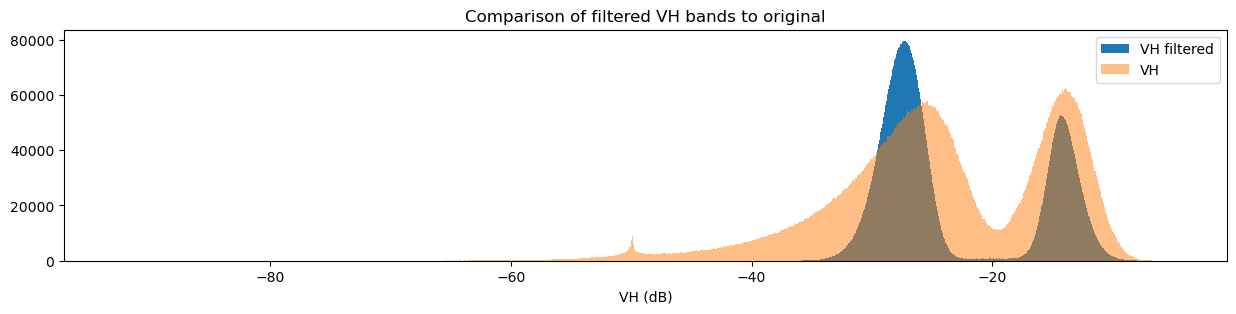
Another way to observe the impact of filtering is to view histograms of the pixel values before and after filtering. Try running the next two cells to view the histograms for VH and VV.
[57]:
fig = plt.figure(figsize=(15, 3))
ds_s1.filtered_vh_dB.plot.hist(bins=1000, label="VH filtered")
ds_s1.vh_dB.plot.hist(bins=1000, label="VH", alpha=0.5)
plt.legend()
plt.xlabel("VH (dB)")
plt.title("Comparison of filtered VH bands to original")
plt.show()
[58]:
fig = plt.figure(figsize=(15, 3))
ds_s1.filtered_vv_dB.plot.hist(bins=1000, label="VV filtered")
ds_s1.vv_dB.plot.hist(bins=1000, label="VV", alpha=0.5)
plt.legend()
plt.xlabel("VV (dB)")
plt.title("Comparison of filtered VV bands to original")
plt.show()
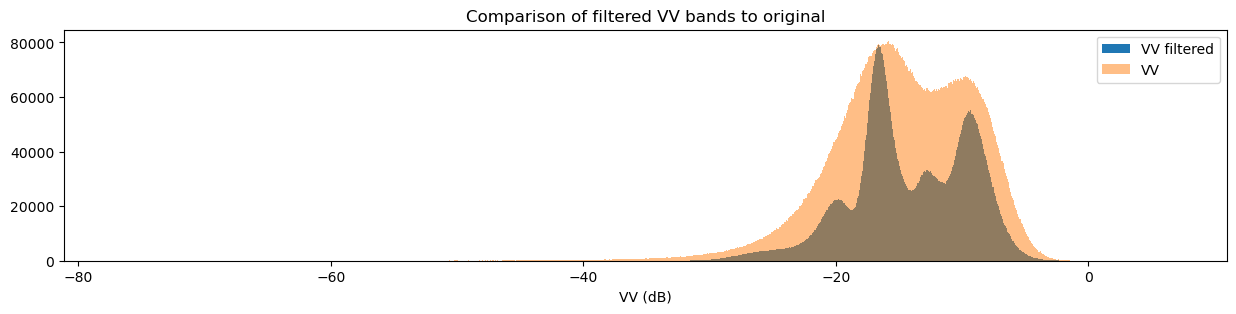
You may have noticed that both the original and filtered bands show two peaks in the histogram, which we can classify as a bimodal distribution. Looking back at the band images, it’s clear that the water pixels generally have lower VH and VV values than the land pixels. This lets us conclude that the lower distribution corresponds to water pixels and the higher distribution corresponds to land pixels. Importantly, the act of filtering has made it clear that the two distributions can be separated, which is especially obvious in the VH histogram. This allows us to confidently say that pixel values below a certain threshold are water, and pixel values above it are land. This will form the basis for our classifier in the next section.
Designing a threshold-based water classifier
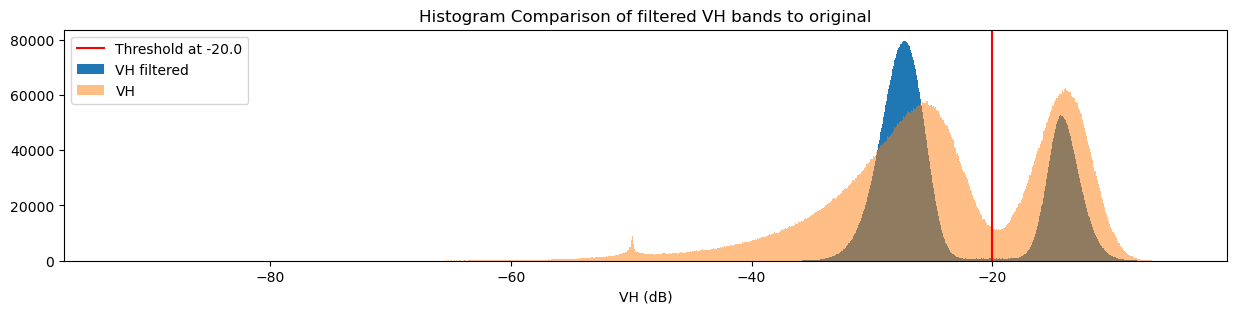
Given that the distinction between the land and water pixel value distributions is strongest in the VH band, we’ll base our classifier on this distribution. To separate them, we can choose a threshold: pixels with values below the threshold are water, and pixels with values above the threshold are not water (land).
There are a number of ways to determine the threshold; one is to estimate it by looking at the VH histogram. From this, we might guess that \(\text{threshold} = -20.0\) is a reasonable value. Run the cell below to set the threshold.
[59]:
threshold = -20.0
The classifier separates data into two classes: data above the threshold and data below the threshold. In doing this, we assume that values of both segments correspond to the same water and not water distinctions we make visually. This can be represented with a step function:
Visualise threshold
To check if our chosen threshold reasonably divides the two distributions, we can add the threshold to the histogram plots we made earlier. Run the next two cells to view two different visualisations of this.
[60]:
fig = plt.figure(figsize=(15, 3))
plt.axvline(x=threshold, label=f"Threshold at {threshold}", color="red")
ds_s1.filtered_vh_dB.plot.hist(bins=1000, label="VH filtered")
ds_s1.vh_dB.plot.hist(bins=1000, label="VH", alpha=0.5)
plt.legend()
plt.xlabel("VH (dB)")
plt.title("Histogram Comparison of filtered VH bands to original")
plt.show()
[61]:
fig, ax = plt.subplots(figsize=(15, 3))
ds_s1.filtered_vh_dB.plot.hist(bins=1000, label="VH filtered")
ax.axvspan(xmin=-40.0, xmax=threshold, alpha=0.25, color="green", label="Water")
ax.axvspan(xmin=threshold,
xmax=-0.5,
alpha=0.25,
color="red",
label="Not Water")
plt.legend()
plt.xlabel("VH (dB)")
plt.title("Effect of the classifier")
plt.show()
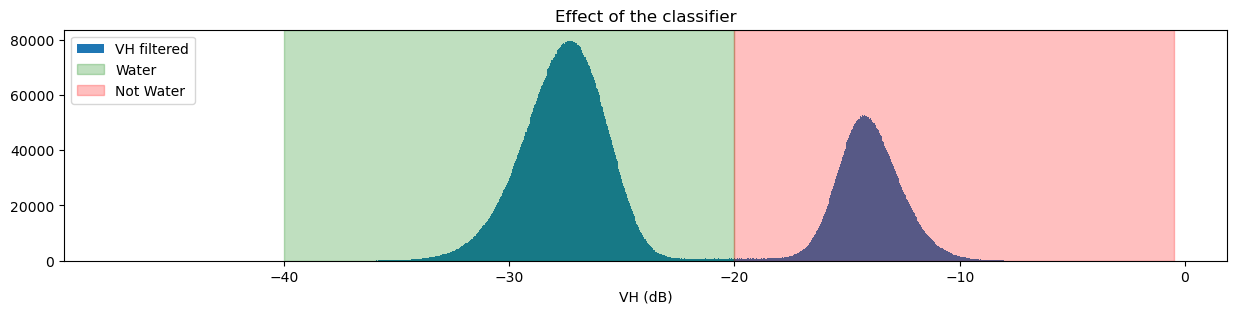
If you’re curious about how changing the threshold impacts the classifier, try changing the threshold value and running the previous two cells again.
Build and apply the classifier
Now that we know the threshold, we can write a function to only return the pixels that are classified as water. The basic steps that the function will perform are:
Check that the data set has a VH band to classify.
Clean the data by applying the speckle filter.
Convert the VH band measurements from digital number (DN) to decibels (dB)
Find all pixels that have filtered values lower than the threshold; these are the
waterpixels.Return a data set containing the
waterpixels.
These steps correspond to the actions taken in the function below. See if you can determine which parts of the function map to each step before you continue.
[62]:
def s1_water_classifier(ds, threshold=-20.0):
assert "vh" in ds.data_vars, "This classifier is expecting a variable named `vh` expressed in DN, not DB values"
filtered = apply_lee_filter(ds_s1.vh, size = 7)
water_data_array = dB_scale(filtered) < threshold
return water_data_array.to_dataset(name="s1_water")
Now that we have defined the classifier function, we can apply it to the data. After you run the classifier, you’ll be able to view the classified data product by running ds_s1.water.
[63]:
ds_s1["water"] = s1_water_classifier(ds_s1).s1_water
[64]:
ds_s1.water
[64]:
<xarray.DataArray 'water' (time: 9, latitude: 1490, longitude: 952)> Size: 13MB
array([[[ True, True, True, ..., False, False, False],
[ True, True, True, ..., False, False, False],
[ True, True, True, ..., False, False, False],
...,
[ True, True, True, ..., True, True, True],
[ True, True, True, ..., True, True, True],
[ True, True, True, ..., True, True, True]],
[[ True, True, True, ..., False, False, False],
[ True, True, True, ..., False, False, False],
[ True, True, True, ..., False, False, False],
...,
[ True, True, True, ..., True, True, True],
[ True, True, True, ..., True, True, True],
[ True, True, True, ..., True, True, True]],
[[ True, True, True, ..., False, False, False],
[ True, True, True, ..., False, False, False],
[ True, True, True, ..., False, False, False],
...,
...
...,
[ True, True, True, ..., True, True, True],
[ True, True, True, ..., True, True, True],
[ True, True, True, ..., True, True, True]],
[[ True, True, True, ..., False, False, False],
[ True, True, True, ..., False, False, False],
[ True, True, True, ..., False, False, False],
...,
[ True, True, True, ..., True, True, True],
[ True, True, True, ..., True, True, True],
[ True, True, True, ..., True, True, True]],
[[ True, True, True, ..., False, False, False],
[ True, True, True, ..., False, False, False],
[ True, True, True, ..., False, False, False],
...,
[ True, True, True, ..., True, True, True],
[ True, True, True, ..., True, True, True],
[ True, True, True, ..., True, True, True]]])
Coordinates:
* time (time) datetime64[ns] 72B 2017-01-25T20:56:21.054081 ... 201...
* latitude (latitude) float64 12kB -11.29 -11.29 -11.29 ... -11.09 -11.09
* longitude (longitude) float64 8kB 130.3 130.3 130.3 ... 130.5 130.5 130.5
spatial_ref int32 4B 4326Assessment with mean
We can now view the image with our classification. The classifier returns either True or False for each pixel. To detect the shoreline, we want to check which pixels are always water and which are always land. Conveniently, Python encodes True = 1 and False = 0. If we plot the average classified pixel value, pixels that are always water will have an average value of 1 and pixels that are always land will have an average of 0. Pixels that are sometimes water and sometimes
land will have an average between these values.
The following cell plots the average classified pixel value over time. How might you classify the shoreline from the average classification value?
[65]:
# Plot the mean of each classified pixel value
plt.figure(figsize=(15, 12))
ds_s1.water.mean(dim="time").plot(cmap="RdBu")
plt.title("Average classified pixel value")
plt.show()
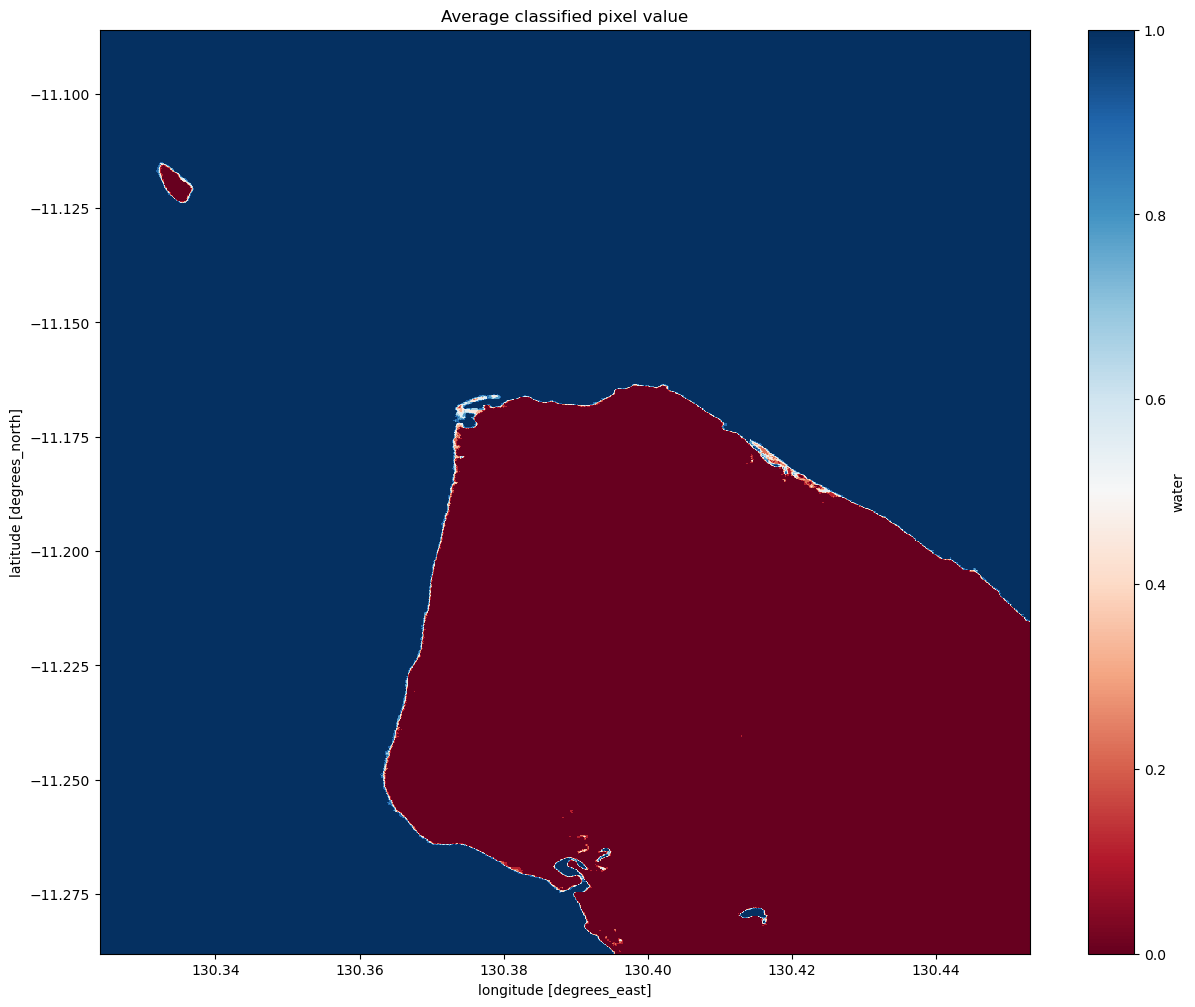
Interpreting the mean classification
You can see that our threshold has done a good job of separating the water pixels (in blue) and land pixels (in red).
You should be able to see that the shoreline takes on a mix of values between 0 and 1, highlighting pixels that are sometimes land and sometimes water. This is likely to due the effect of rising and falling tides, with some radar observations being captured at low tide, and others at high tide.
Assessment with standard deviation
Given that we’ve identified the shoreline as the pixels that are calssified sometimes as land and sometimes as water, we can also see if the standard deviation of each pixel in time is a reasonable way to determine if a pixel is shoreline or not. Similar to how we calculated and plotted the mean above, you can calculate and plot the standard deviation by using the std function in place of the mean function.
If you’d like to see the results using a different colour-scheme, you can also try substituting cmap="Greys" or cmap="Blues" in place of cmap="viridis".
[66]:
# Plot the standard deviation of each classified pixel value
plt.figure(figsize=(15, 12))
ds_s1.water.std(dim="time").plot(cmap="viridis")
plt.title("Standard deviation of classified pixel values")
plt.show()
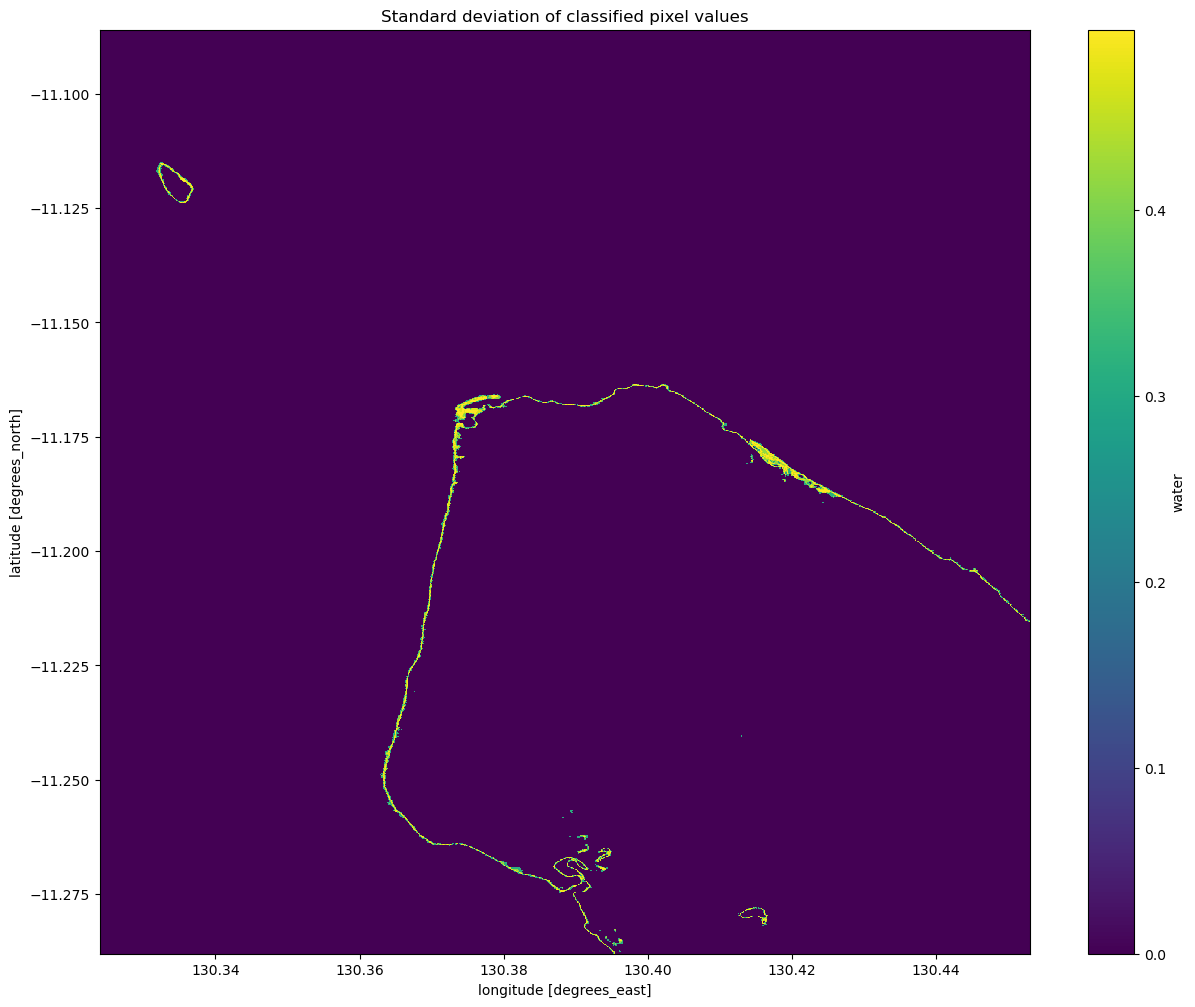
Interpreting the standard deviation of the classification
From the image above, you should be able to see that the land and water pixels almost always have a standard deviation of 0, meaning they didn’t change over the time we sampled. Areas along the coastline however have a higher standard deviation, indicating that they change frequently between water and non-water (potentially due to the rise and fall of the tide). With further investigation, you could potentially turn this statistic into a new classifier to extract shoreline pixels. If you’re
after a challenge, have a think about how you might approach this.
An important thing to recognise is that the standard deviation might not be able to detect the difference between noise, tides and ongoing change, since a pixel that frequently alternates between land and water (noise) could have the same standard deviation as a pixel that is land for some time, then becomes water for the remaining time (ongoing change or tides). Consider how you might distinguish between these different cases with the data and tools you have.
Detecting change between two images
The standard deviation we calculated before gives us an idea of how variable a pixel has been over the entire period of time that we looked at. It might also be interesting to look at which pixels have changed between any two particular times in our sample.
In the next cell, we choose the images to compare. Printing the dataset should show you that there are 9 time-steps, so the first has an index value of 0, and the last has an index value of 8. You can change these to be any numbers in between, as long as the start is earlier than the end.
[67]:
start_time_index = 0
end_time_index = ds_s1.water.sizes["time"] - 1
Next, we can define the change as the difference in the classified pixel value at each point. Land becoming water will have a value of -1 and water becoming land will have a value of 1.
[68]:
change = np.subtract(ds_s1.water.isel(time=start_time_index),
ds_s1.water.isel(time=end_time_index),
dtype=np.float32)
# Set all '0' entries to NaN, which prevents them from displaying in the plot.
change = change.where(change != 0)
ds_s1["change"] = change
Now that we’ve added change to the dataset, you should be able to plot it below to look at which pixels changed. You can also plot the original mean VH composite to see how well the change matches our understanding of the shoreline location.
[69]:
plt.figure(figsize=(15, 12))
ds_s1.filtered_vh_dB.mean(dim="time").plot(cmap="Blues")
ds_s1.change.plot(cmap="RdBu", levels=2)
plt.title(f"Change in pixel value between time={start_time_index} and time={end_time_index}")
plt.show()
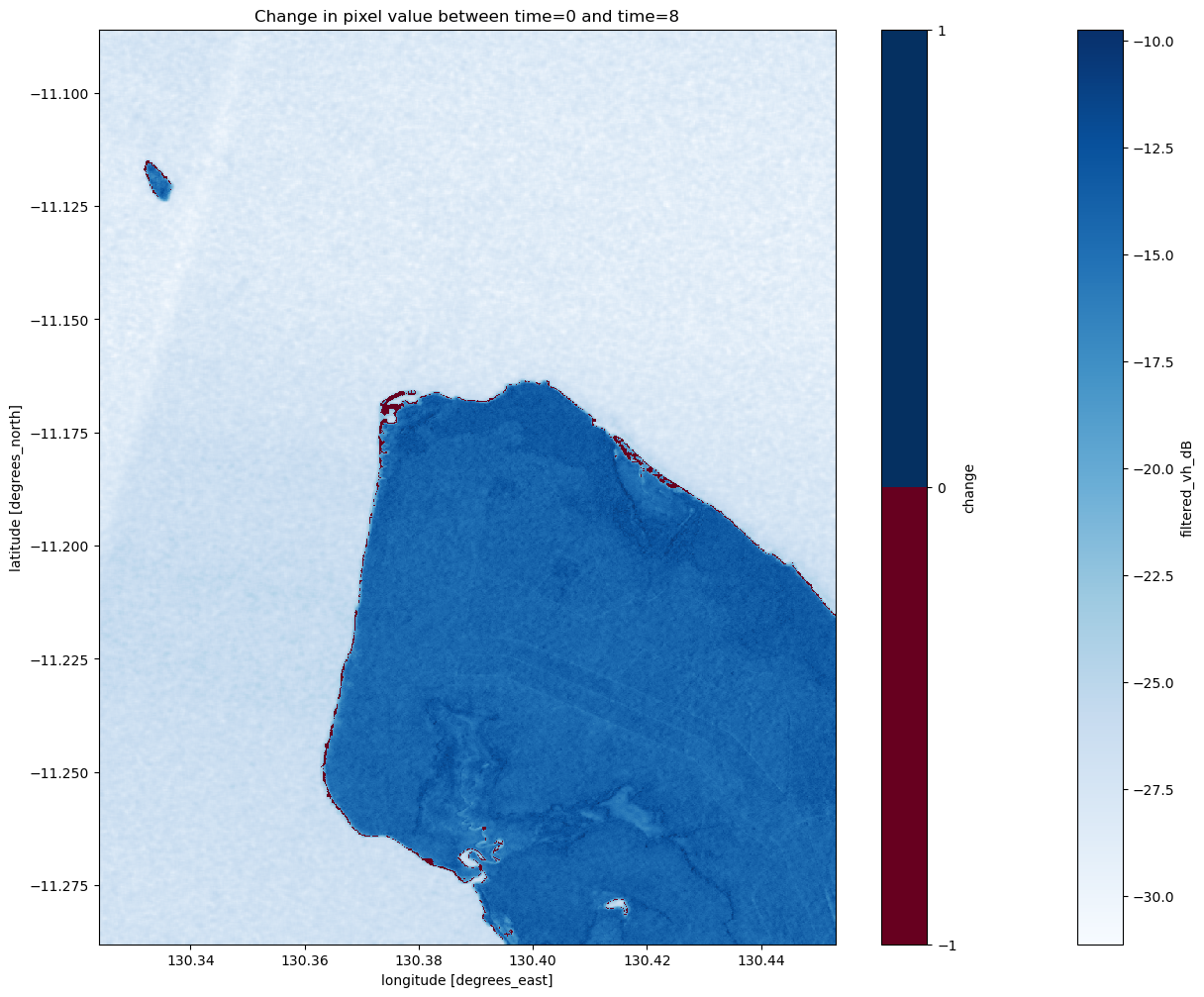
Coastal change or tides?
Tides can greatly affect the appearance of the coastline, particularly along northern Australia where the tidal range is large (up to 12 m). Without additional data, it is difficult to determine whether the change above is due to the coastline having eroded over time, or because the two radar images were captured at different tides (e.g. low vs. high tide). The radar water classifier in this notebook could potentially be combined with tidal modelling from the Coastal Erosion notebook to look into this question in more detail.
Drawing conclusions
Here are some questions to think about:
What are the benefits and drawbacks of the possible classification options we explored?
How could you extend the analysis to extract a shape for the coastline?
How reliable is our classifier?
Is there anything you can think of that would improve it?
Next steps
1. Select another Australian area using DEA Data
When you are done, return to the “Analysis parameters” section, modify some values (e.g. latitude and longitude) and rerun the analysis. You can use the interactive map in the “View the selected location” section to find new central latitude and longitude values by panning and zooming, and then clicking on the area you wish to extract location values for. You can also use Google maps to search for a location you know, then retrieve the latitude and longitude values by clicking the map.
If you’re going to change the location, you’ll need to make sure Sentinel-1 data is available for the new location, which you can check on the DEA Explorer.
2. Investigate Global Areas (excl. Antarctica) using Microsoft Planetary Computer Data
Currently, the DEA datacube has a limited amount of analysis-ready Sentinel-1 data. To extend our analysis to other areas of the globe, we are able to make use of the Microsoft’s Planetary Computer catalog of satellite and environmental data. This data is accompanied by detailed SpatioTemporal Asset Catalog (STAC) metadata, which makes it possible to search and discover data from specific products, time periods and locations of interest.
See more about combining Microsoft Planetary Compute data and DEA data here: Planetary_computer.ipynb
See more about the Sentinel-1-RTC product here: https://planetarycomputer.microsoft.com/dataset/sentinel-1-rtc
[70]:
# Import extra libraries
import pystac_client
import planetary_computer
import odc.stac
import odc.geo.xr
from odc.geo.geom import BoundingBox
[71]:
# this is the same as the top of the notebook,
# but we can change to other areas of interest
latitude = (-11.288, -11.086)
longitude = (130.324, 130.453)
time = ("2020-01", "2020-02")
[72]:
# Open a client pointing to the Microsoft Planetary Computer data catalogue
catalog = pystac_client.Client.open(
"https://planetarycomputer.microsoft.com/api/stac/v1",
modifier=planetary_computer.sign_inplace,
)
[73]:
# Convert data-cube style queries into something readable by `pystac_client`
bbox = BoundingBox.from_xy(longitude, latitude)
time_range = "/".join(time)
# Search for STAC items from "esa-worldcover" product
search = catalog.search(
collections="sentinel-1-rtc",
bbox=bbox,
datetime=time_range,
)
# Check how many items were returned
items = search.item_collection()
print(f"Found {len(items)} STAC items")
Found 5 STAC items
Loading data using odc-stac
Once we have found some data, we can load it into our notebook using the odc-stac Python library. The odc.stac.load function works similarly to dc.load, allowing us to load one or more bands of data into an xarray.Dataset().
Here we will load sentinel-1 RTC data for our study area into Australian Albers 20 m pixels.
Note: The
odc.stac.loadfunction uses slightly different terminology todc.load, for example: “bands” vs “measurements”, “groupby” vs “group_by”, “chunks” vs “dask_chunks”.
[74]:
# Load sentinel-1 RTC data with odc-stac
ds_s1 = odc.stac.load(
items,
bbox=bbox,
crs="EPSG:3577",
resolution=20,
)
# Inspect outputs
ds_s1
[74]:
<xarray.Dataset> Size: 32MB
Dimensions: (y: 1102, x: 736, time: 5)
Coordinates:
* y (y) float64 9kB -1.166e+06 -1.166e+06 ... -1.188e+06 -1.188e+06
* x (x) float64 6kB -1.874e+05 -1.874e+05 ... -1.728e+05 -1.727e+05
spatial_ref int32 4B 3577
* time (time) datetime64[ns] 40B 2020-01-10T20:56:36.059834 ... 202...
Data variables:
vh (time, y, x) float32 16MB 0.003807 0.004765 ... 0.03516 0.07016
vv (time, y, x) float32 16MB 0.03688 0.04085 ... 0.1356 0.1253[75]:
# Scale to plot data in decibels
ds_s1["vh_dB"] = dB_scale(ds_s1.vh)
# Plot all VH observations for the year
ds_s1.vh_dB.plot(cmap="Greys_r", robust=True, col="time", col_wrap=5)
plt.show()

By changing the latitude and longitude values, we can now extend our analysis to other places.
Additional information
License: The code in this notebook is licensed under the Apache License, Version 2.0. Digital Earth Australia data is licensed under the Creative Commons by Attribution 4.0 license.
Contact: If you need assistance, please post a question on the Open Data Cube Discord chat or on the GIS Stack Exchange using the open-data-cube tag (you can view previously asked questions here). If you would like to report an issue with this notebook, you can file one on
GitHub.
Last modified: August 2024
Compatible datacube version:
[76]:
print(datacube.__version__)
1.8.19
Tags
Tags: sandbox compatible, sentinel 1, display_map, real world, speckle filtering, water, radar, coastal erosion, intertidal